
Artificial Intelligence and Computer Vision Lab
University of Arkansas, Computer Science and Computer Engineering, 2020
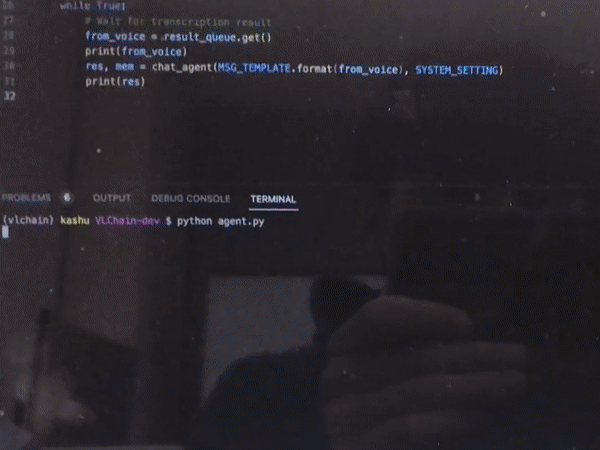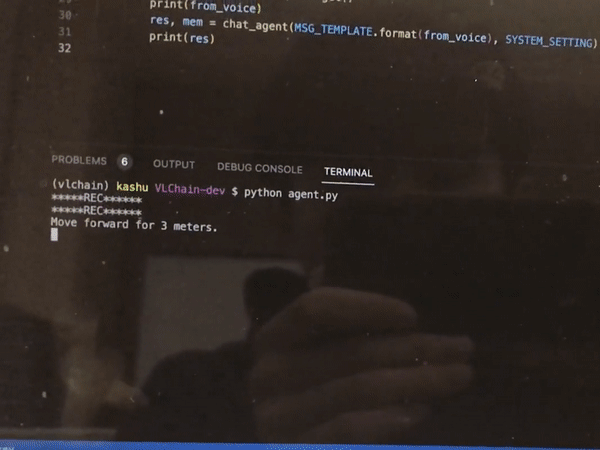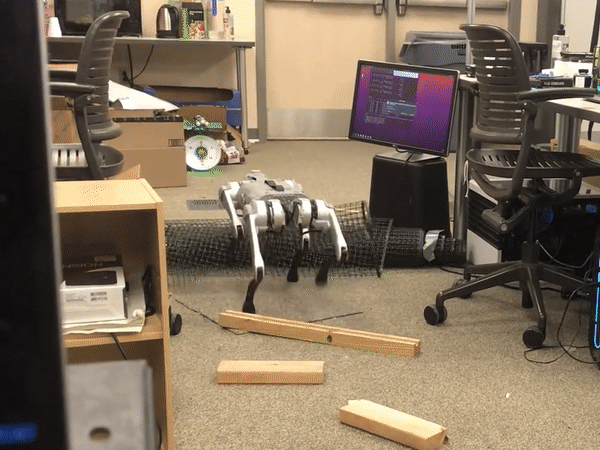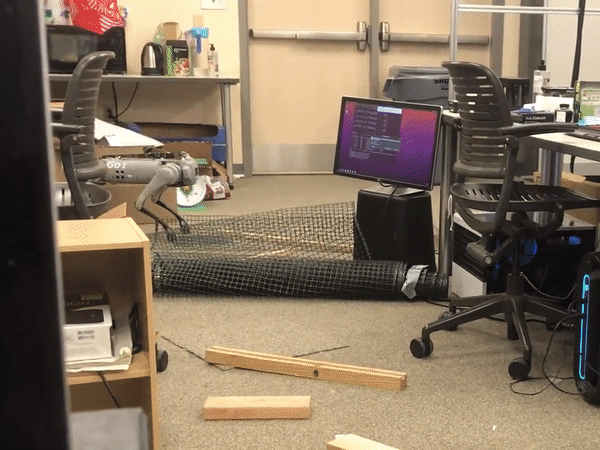
Vision and Language Grounding for Robotics
coming soon…
Explainable Representation Learning for Video Understanding
Extracting contextual visual representation from untrimmed videos is challenging due to their long and complex temporal structure. While existing approaches typically rely on pre-trained backbone networks to extract visual representation, we take a different approach, focusing on extracting the most contextual information in an explainable manner.
Application in Action Proposal

Temporal action proposal generation (TAPG) is a challenging task, which requires localizing action intervals in an untrimmed video. Given an untrimmed video $\mathcal{V}$, our goal is to generate a set of temporal segments $a_i = (s_i, e_i) |_{i=1}^{M}$ which inclusively and tightly contain actions of interest. Where an action segment comprised of a starting timestamp ($s_i$) and an ending timestamp ($e_i$).
Comprehensive experiments and extensive ablation studies on ActivityNet−1.3 and THUMOS-14 datasets show that our proposed AOE-Net outperforms previous state-of-the-art methods with remarkable performance and generalization for both TAPG and temporal action detection.
Application in Captioning

Video paragraph captioning aims to generate a multi-sentence description of an untrimmed video in coherent storytelling given the event boundaries. Given an untrimmed video $\mathcal{V}$ and event boundaries $a_i = (s_i, e_i) |_{i=1}^{M}$, our goal is to generate a coherent paragraph $\mathcal{P}$ with $M$ sentences that describes the whole video $\mathcal{V}$.
We proposed an autoregressive Transformer-in-Transformer (TinT) to simultaneously capture the semantic coherence of intra- and inter-event contents within a video. Comprehensive experiments and extensive ablation studies on ActivityNet Captions and YouCookII datasets show that the proposed Visual-Linguistic Transformer-in-Transform (VLTinT) outperforms prior state-of-the-art methods on both accuracy and diversity.
Open Vocabulary Models for Semantic Understanding
Open vocabulary recognition has recently attracted a lot of attention in computer vision as it allows to perform language-conditioned unbounded understanding.



Learning High-Agility Locomotion for Quadrupeds
While quadrupeds can open the operational domains of robots thanks to their dynamic locomotion capabilities, conventional controllers for legged locomotion constraint their applications to relatively simple environments that can be taken over by wheeled robots. We utilize a reinforcement learning and representation learning to acquire the high-agility locomotion skills for quadrupeds.
Massively Parallel Reinforcement Learning

Here we use massively parallel RL to train a quadruped to walk on various terrains. In the simulation, a quadruped learns to walk across challenging terrain, including uneven surfaces, slopes, stairs, and obstacles, while following linear- and angular- velocity commands. We evaluate our learnt policies on a real Unitree Go1 robot. We find that our policies trained entirely in simulation are able to transfer to the real world zero-shot.

Memory Efficient Model for Medical Imaging
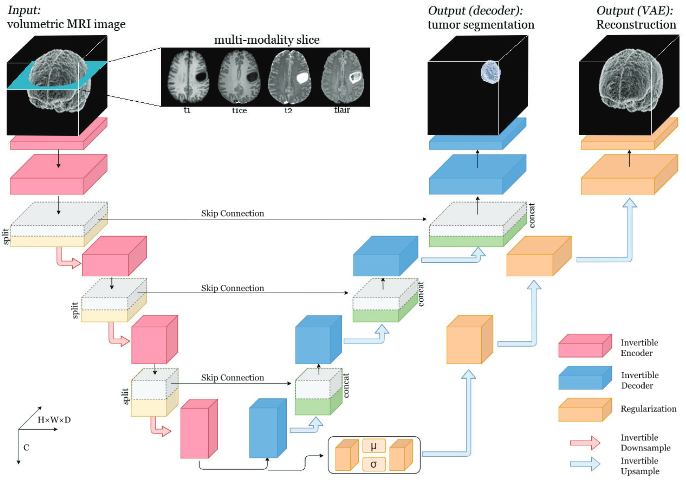 In medical imaging, we frequently work with volumetric data, which can be challenging to process computationally. To tackle this issue, we have developed a fully invertible residual network that utilizes bijective operations to reduce the memory footprint during training. Our volume-preserving approach has proven to be highly effective in reducing memory demands during training. By implementing this technique, we have successfully reduced memory requirements by approximately 50% compared to the baseline model, without compromising the performance.
In medical imaging, we frequently work with volumetric data, which can be challenging to process computationally. To tackle this issue, we have developed a fully invertible residual network that utilizes bijective operations to reduce the memory footprint during training. Our volume-preserving approach has proven to be highly effective in reducing memory demands during training. By implementing this technique, we have successfully reduced memory requirements by approximately 50% compared to the baseline model, without compromising the performance.